是否曾經看過一張 table 大到 1TB 以上 Query 起來速度非常慢?
這個章節我們將介紹 db 如何切表,然後介紹 Partition 與 Sharding。
在以前的學習過程中是否
Partition/Sharding 傻傻分不清楚,
Cluster/Distribution 傻傻分不清楚
呢?
這個章節希望能讓大家能夠更清楚,其中也會介紹一些工具來輕鬆達成目標。
一般來說只要是將一張表切割,而那一塊一塊的子表,通常會分成兩類。

這裡我們先定義一下名詞,
原表我們暫稱 Main Table,
子表暫稱 Partition Table,
以便後續好講解。
這個例子將員工資料與照片切出來,這樣撈出一筆紀錄時,就不需要一同連肥大的圖片也撈出。
確實是個好案例,但不是一個好設計,不建議將 db 存圖片喔!
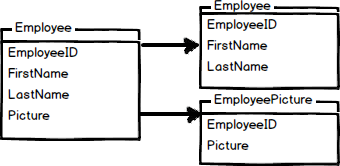
比較常使用的案例像是同類但又不太一樣的東西,我們就會做簡單的切表。
像是 account 底下有 admin,user, maintainer 這三類,
有些設計可能會建立 account table,將該三個角色所需欄位取交集,像這樣。
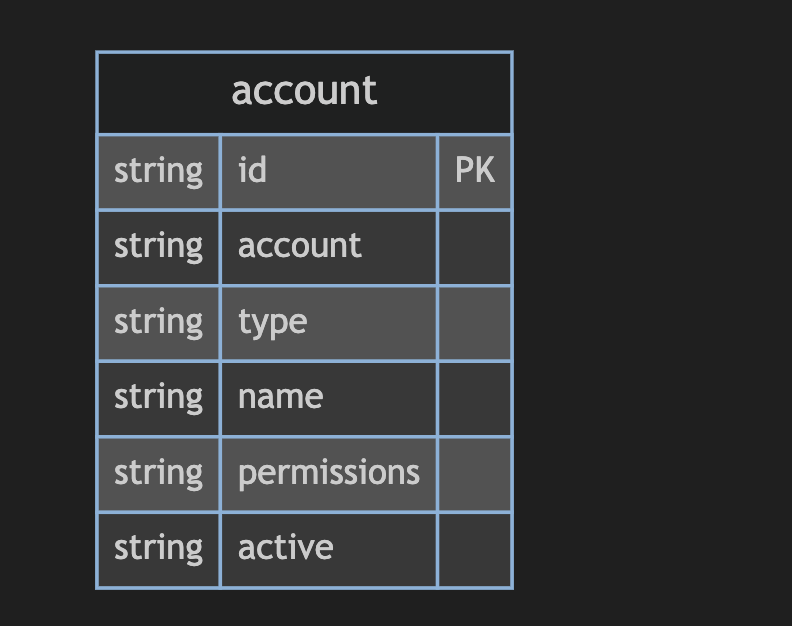
這樣非常奇怪,在程式之中會寫成一個父物件、三個子類別,
但在 ERD 上卻完全擠在一起,當欄位一多時看起來更是髒亂。
其實可以將 account 做一張表,拿來做與其他 table 的關聯與查詢,
而 admin、user、maintainer 會因個別不同的特性,所以建立三張表。
最後作法可能如下
Horizontal Partitioning
我們還可以藉由 Range、List、Hash 等方式來做 partition,
不只如此,還可以在做完一次 Partition 後,再做一個 secondary partition。
CREATE TABLE sales (id int, ..., sale_date date)
PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2019_Q4 PARTITION OF sales FOR VALUES FROM ('2019-10-01') TO ('2020-01-01');
CREATE TABLE sales_2020_Q1 PARTITION OF sales FOR VALUES FROM ('2020-01-01') TO ('2020-04-01');
CREATE TABLE sales_2020_Q2 PARTITION OF sales FOR VALUES FROM ('2020-04-01') TO ('2020-07-01');
時間是一個永無止境的切割方式,
我們可以自行撰寫 cronjob 來新增 partition。
或透過 pg_partman 等工具來協助完成。
CREATE TABLE sales_region (id int,..., region text)
PARTITION BY LIST (region);
CREATE TABLE London PARTITION OF sales_region FOR VALUES IN ('London');
CREATE TABLE Sydney PARTITION OF sales_region FOR VALUES IN ('Sydney');
CREATE TABLE Boston PARTITION OF sales_region FOR VALUES IN ('Boston');
這裡直接建立了三個 region,只要 region 符合,
insert 資料時就會依照 region 分別放入對應的 table。
CREATE TABLE emp (emp_id int,... )
PARTITION BY HASH (emp_id);
CREATE TABLE emp_0 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 0);
CREATE TABLE emp_1 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 1);
CREATE TABLE emp_2 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 2);
Sharding 其實是 Horizontal Partition 的演進,
使用Sharding結構如下圖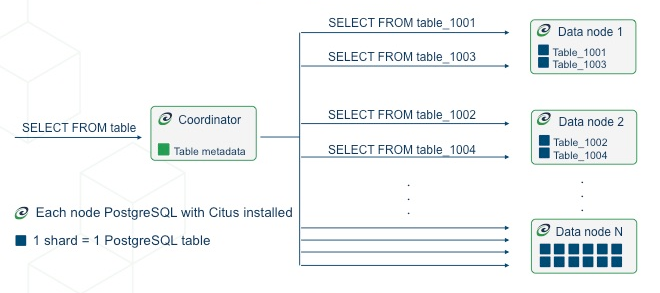
相較於 Sharding,Horizontal Partition 長下圖這樣,
只是所有的 Partition Table 都在同一個節點內。
而 Sharding 機制,再將 Partition Table 做一層包裹,
就如果 k8s 利用 pod 來包 container,將 pod 作為各個 node 間的調度單位。
而 Sharding 就如同 pod 一樣作為 Partition Table 的調度單位,
而 Partition Table 就如同 container 一樣,是真實的資料來源。
當一個 Sharding 只包一個 Partition Table 時,會變成 1shard=1postgres table。
我們也可以看到上圖,左下角也有寫 1shard=1 pg table。
在架構上我們可以讓每個 db server 擁有所有或部分 shard,
擁有所有 shard 就如同做 replica 一樣,每一座 db server 都有完整的資料。
擁有部分 shard 將資料分散到不同 db server,讓降低單台壓力。
在 pg 我們可以透過 Vitess,Citus 等插件來建立 Shard 達到相對應的效果。
回憶一下我們剛剛做 Partition 建立 Main Table 時。
CREATE TABLE sales (id int, ..., sale_date date)
PARTITION BY RANGE (sale_date);
這裡的 sale_date 其實就是我們所謂的 Shard key,
可以說是主表在做 query 時,拿來找 Partition Table 時的 key,
當找到對應的 key 時,我們就可以找到對應的 Partition Table,再來找到對應的該筆資料。
而 Sharding 相同的也有類似 Main Table 的東西,
他有許多名稱,如 meta table,super table 等等。
這些都是透過 Shard Key 在上層來做 index,指向對應的 shard,
然後再進入 shard 做 query。
而各個 db server 間同步的方式主要分為兩類,
是否 Cluster 與 Distribution 傻傻分不清楚呢?
筆者以前剛學習時也分不清楚鬧了許多笑話,
其實兩者與資料庫的機制與設計完全無關,
只是那些機制與設計在這兩個之間會經常使用。
那麼主要的差異在哪裡呢?入口是主要的差異。
Cluster 重點在 HA 與 fail over,實際上入口都是同一個點,
只是後面的 HA 做了分流,將請求流向不同的 server 上。
如 read/write split,sentinel,cluster 等 pattern。
我們可以透過 postgres XL 來建立一個 Postgres Cluster。
Distribution 重點在多主入口,每個主都有完整的資料與服務。
你當然可以在每個主節點上也建立 Cluster,變成 Distribution Cluster。
這裡就已經幾乎不可能達到強一制性了,否則就要付出極大的成本。
我們可以透過 postgres Edge 來建立一個 Distribution Postgres System。
因為這兩者的設計都是會跨 server, 所以有需多同步方式與概念都會是相同的。
也因為這裡可以分配部分 db 做 OLAP,部分 db 做 OLTP,所以常常會說這裡達到了 HTAP。
這裡的內容先簡單提及,未來將會在下集做進一步的介紹。
Cluster: 2pc,wal,saga...
Distribution: Gossiping alg,saga,p2p...
還有許許多多知識點需要介紹,一不小心好像挖太多坑了,
不過沒關係,學習就像是瞎子摸象一樣,會越摸越清楚,
上集先以單體式資料庫為主要探討點,
再來以分散式資料庫議題做更深入的探討。
建構 Cluster 與 Distribution 環境並不會是主要難題。
困難的是能將其掌握之中,針對問題做出對應的正確反應與設計,
並且操作自如清楚避開所有 side effect。
相較於 Horizontal Partition,Horizontal Partition 長下圖這樣,
這邊打錯了
感謝糾錯,已修正


 iThome鐵人賽
iThome鐵人賽